Efficient SSG with CSP
In this post, I'm going to discuss my new static site generator which uses communicating sequential processes (also known as "actors") to efficiently build a static site from source, improving performance on the order of 10X (on my laptop) by efficiently using all available cores.
Intro to SSGs
For those who don't know, a static site is a website that is just some HTML files served up by a simple web server, as opposed to a more typical website which generates HTML files on the fly based on content stored in a database. Static sites are simpler and they can be made more performant more easily than dynamic websites, but they're also more limited. They're really optimal for pure-read workloads, like this blog. A static site generator allows users to author pages as markdown files in a directory (e.g., stored in Git) which the static site generator will take as input and yield corresponding HTML pages as output.
For my blog use case, I write my posts as markdown files in a posts directory
and the static site generator converts them to output HTML pages but it also
builds index pages which list the posts available on my site in order.
Here is a post page,
here
is the markdown source for that same page, and here is an index
page.
Intro to CSP
Communicating sequential process is a way of structuring programs so they can be parallelized efficiently and with minimal hassle. Typically, writing parallel programs requires tedious and error prone coordination of locking mutable state, whereas CSP involves writing code as sequential processes (which I'll be refering to as "actors") which each assume ownership over their internal state (thereby no need to lock) and which communicate with each other using threadsafe channels (in this case, we'll be using Go channels).
Additionally, each actor has a "concurrency" or a number of replicas which are reading from a shared input channel and writing to a shared output channel, however, each replica has its own copy of the internal state which is kept private from the other replicas.
Finally, to ensure that each channel is closed exactly once (if we close a Go channel multiple times it will panic, and if we don't close it then the program will typically deadlock), I'm using the convention that each actor "owns" its output channel and "borrows" its input channel. Ownership in the context of channels means "assuming responsibility for closing the channel"--a channel can have only one owner but potentially many borrowers, although in my program each channel has one owner and one borrower. When the first actor completes its work, it closes its channel which causes downstream actors to shutdown and close their channels.
SSG stages
However you build it, a static site generator for a blog has to do the following (at a minimum):
- Iterate over the source markdown post files
- Parse the metadata out of the markdown post files and convert the markdown to HTML (and patch links so they resolve correctly in the output HTML, but we won't dive into that in this post)
- Collect all of the parsed posts and order them so we can build index pages
- Render the post pages (pass the post data structure to the post template1 and write the result to disk)
- Render the index pages (pass the index page data structure to the index page template1 and write the result to disk)
SSG with CSP
To leverage CSP to parallelize my SSG, I'm roughly modeling each SSG stage as an actor:
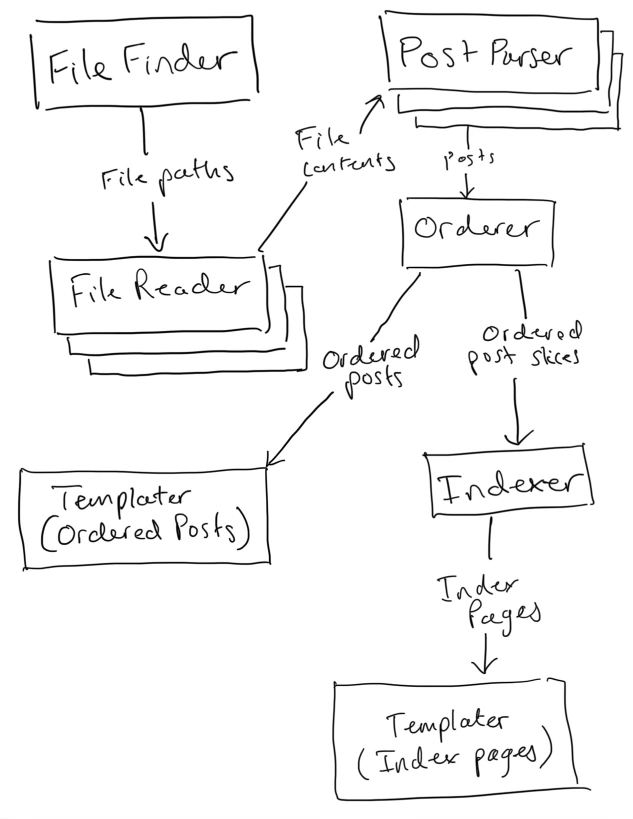
- FileFinder::PostSources
- Concurrency: 1
- Input channels: 0
- Output channels: 1 (markdown file paths)
- Description: this actor scans an input posts directory for
.mdfiles. It doesn't open the files, but rather it sends each file path down its output channel.
- FileReader
- Concurrency: 4 (based on some calibration for my laptop; because this is an I/O bound workload, it's largely an artifact of my laptop's ability to write concurrent data streams)
- Input channels: 1 (file paths)
- Output channels: 1 (file contents)
- Description: this actor runs several replicas in parallel, each pulling a file path from the input channel, reading its contents, and writing them to the output channel.
- PostParser
- Concurrency: 8 (based on calibration for my laptop; because it's a purely CPU-bound workload, this figure is predominately an artifact of my laptop's CPU core count)
- Input channels: 1 (file contents)
- Output channels: 1 (posts)
- Description: this actor runs several replicas in parallel, each pulling the file contents from the input channel, parsing out the metadata (the title, date, author, etc), and converting the markdown body to HTML (this latter step is the most time-consuming operation in the entire system--moreso even than the disk I/O) before writing the resulting post data structure to the output channel.
- Orderer
- Concurrency: 1 (while this is CPU-bound, it takes virtually no time to execute)
- Input channels: 1 (posts)
- Output channels: 2 ("ordered posts"--posts which know about the post before and after them--and an "ordered posts slice" which is a slice of all of the ordered post data structures ordered by date)
- Description: collects all posts, orders them by date, and attaches next/previous links to each post. It writes the slice of ordered posts to the "ordered posts slice" output channel and closes it. It also iterates over the slice and writes each item to the "ordered posts" output channel before closing it.
- Indexer
- Concurrency: 1
- Input channels: 1 (ordered posts slices)
- Output channels: 1 (index pages)
- Description: it reads the ordered posts slice from its input channel and indexes the posts by their tags. It then paginates each index so there are 10 posts per index page, and it attaches next and previous links to each index page. It writes all index pages to its output channel.
- Templater[Post]
- Concurrency: 8
- Input channels: 1 (ordered posts)
- Output channels: 0 (it writes to disk)
- Description: each replica reads an ordered post from its input channel and applies the post template, writing the output file to the output posts directory on disk.
- Templater[IndexPage]
- Concurrency: 8
- Input channels: 1 (index pages)
- Output channels: 0 (it writes to disk)
- Description: each replica reads an index page from its input channel and applies the index template, writing the output file to the output posts directory on disk.
Result
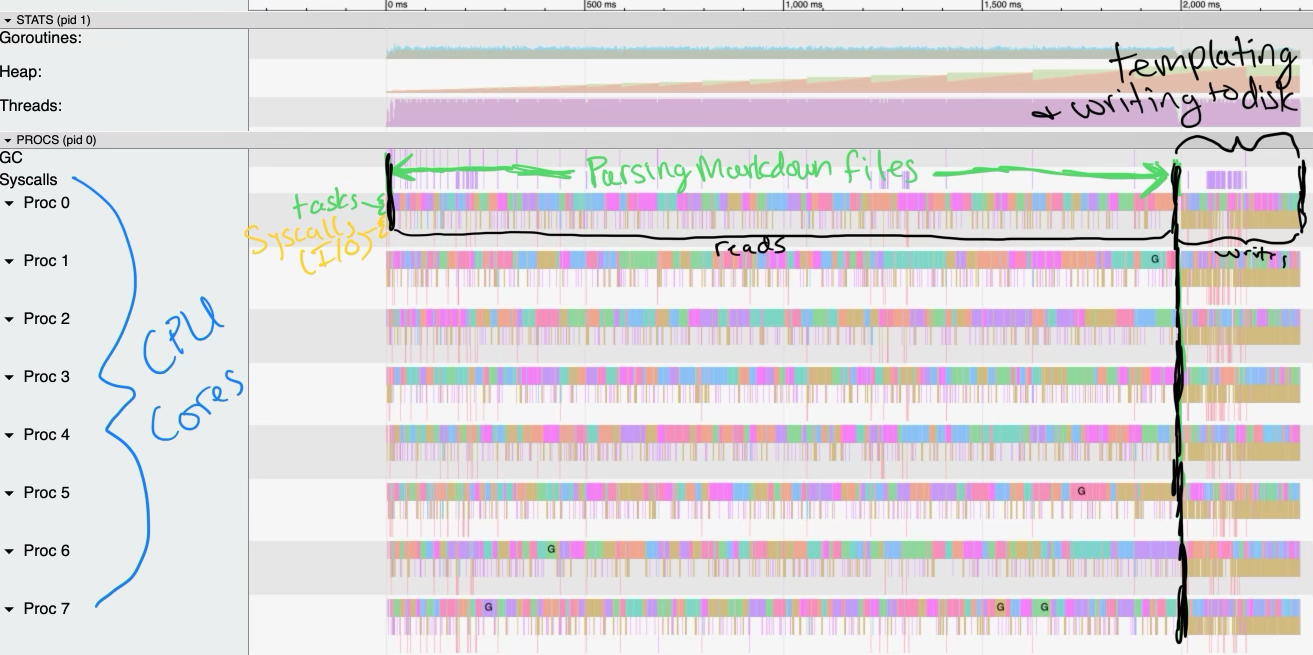
Pardon the MS-paint-quality annotations, but the following image indicates that
the program is fully utilizing the 8 CPU cores (no whitespace in the colored
horizontal bars). The black vertical line indicates the moment all of the parsed
posts are collected and ordered by the Orderer actor--all of the preceding
work is parsing the post files and all of the subsequent work is templating and
writing the output files to disk. The brownish-yellow bars below each
multi-colored bar are the syscalls (essentially the disk I/O).
The entire batch of 1000 posts completes in a little over 2 seconds, whereas the single-threaded version took about 20 seconds. Notably, however, switching to the actor architecture even improved performance with a single CPU core because CPU work could run while the process was awaiting disk I/O--it took about 15 seconds with the single-core actor version versus the 20 seconds of the single-threaded imperative version.
I'm using Go templates, and I have one post template file, one index template file which each inherit from a base template file (the latter defines things which are common to both, such as the site header and footer and the CSS). The post and index template files each take a post or index page (respectively) and generate the output HTML for that page--they aren't doing any markdown->html conversion as that aleady takes place during the parsing stage.